Der Kern der Änderung wird häufig missverstanden. Atlassian hat Metadaten und In-App-Daten von Kundenorganisationen bereits zuvor verarbeitet und genutzt, allerdings ausschließlich zur Verbesserung der jeweiligen Kundeninstanz. Neu ist nun die erweiterte Reichweite dieser Nutzung: Künftig dürfen die Daten auch zur Weiterentwicklung der Plattform für alle Kundenorganisationen herangezogen werden. Dabei handelt es sich um eine substanzielle, zugleich aber klar eingrenzbare Erweiterung. Gerade diese begriffliche Präzision sollte auch den Maßstab für die interne Bewertung bilden.
Auf einen Blick
- Ab dem 17. August 2026 kann Atlassian bestimmte Cloud-Daten zur Verbesserung der Plattform für sämtliche Kundenorganisationen verwenden.
- Betroffen sind nicht nur technische Metadaten, sondern — abhängig von den gewählten Einstellungen — auch Inhalte aus Jira, Confluence und Jira Service Management.
- Welche Optionen zur Verfügung stehen, richtet sich nach dem jeweils höchsten aktiven Plan; bei Free-, Standard- und Premium-Plänen lassen sich Metadaten nicht deaktivieren.
- Vor dem Stichtag sollte jede Organisation bewusst und nachvollziehbar entscheiden, ob und in welchem Umfang sie Daten für diese Zwecke bereitstellen möchte.
Was sich ändert
Atlassian unterscheidet künftig zwischen zwei Datenkategorien, die zur kollektiven Verbesserung der Plattform herangezogen werden können: Metadaten und In-App-Daten.
Metadaten umfassen statistische Eigenschaften und abgeleitete Informationen, etwa Story Points, Lesbarkeits-Scores für Confluence-Seiten, algorithmisch zugewiesene Intent-Klassifikationen oder SLA-Werte. Dazu zählen auch sogenannte „Common Patterns“: wiederkehrende Formulierungen und Themen aus Suchanfragen, Konfigurationsdaten und Rovo-Interaktionen, sofern diese über viele Kundenorganisationen hinweg in ähnlicher Form auftreten.
In-App-Daten beziehen sich hingegen auf Inhalte, die Nutzende aktiv erstellen: etwa Titel und Texte von Confluence-Seiten, Titel, Beschreibungen und Kommentare in Jira-Vorgängen sowie individuelle Emoji-Namen oder eigene Status- und Workflow-Bezeichnungen. Gerade dieser Aspekt wird in vielen Diskussionen unterschätzt. Wer bei „Daten zur KI-Verbesserung“ vor allem an abstrakte Telemetrie denkt, sollte berücksichtigen, dass unter Umständen auch konkrete Inhalte aus Tickets und Wiki-Seiten in die Verarbeitung einbezogen werden können.
Wer betroffen ist und wer nicht
Bestimmte Kundengruppen sind vollständig von der Änderung ausgenommen: Dazu zählen Organisationen mit eigenen Verschlüsselungsschlüsseln (BYOK beziehungsweise Customer-Managed Keys), die Atlassian Government Cloud, die Atlassian Isolated Cloud, Kunden mit HIPAA-Verpflichtungen sowie ausgewählte Government- und Financial-Services-Kunden. Für diese Organisationen werden weder Metadaten noch In-App-Daten zur Verbesserung der Plattform für andere Kundenorganisationen verwendet; zudem steht die entsprechende Einstellung in der Administration nicht zur Verfügung.
Welche Optionen einer Organisation angeboten werden, richtet sich nach dem jeweils höchsten aktiven Plan sowie nach bestimmten Compliance-Anforderungen. Die folgende Tabelle zeigt die Abgrenzung der einzelnen Segmente, ihre jeweiligen Standardeinstellungen und die verfügbaren Steuerungsoptionen.
|
Kontrollniveau |
Ausgeschlossene Kunden |
Volle Kontrolle |
Eingeschränkte Kontrolle |
|
Segment |
Regulierte Branchen und Compliance-Kunden |
Cloud Enterprise |
Free, Standard, Premium |
|
Kriterium |
Spezifische Compliance-Anforderungen sowie bestimmte Government- und Financial-Services-Kunden |
Höchster aktiver Plan = Cloud Enterprise |
Höchster aktiver Plan = Free, Standard oder Premium |
|
Standard und verfügbare Einstellungen |
Daten sind vollständig vom Beitrag ausgeschlossen Keine Möglichkeit, die Beitragsleistung zu aktivieren |
Metadaten: standardmäßig an, mit Möglichkeit zur Deaktivierung In-App-Daten: standardmäßig aus, mit Möglichkeit zur Aktivierung |
Metadaten: standardmäßig an, keine Opt-out-Option Premium: In-App-Daten standardmäßig aus, mit Aktivierungsoption Standard und Free: In-App-Daten standardmäßig an, mit Deaktivierungsoption |
|
Empfohlene Maßnahme |
Keine Maßnahme erforderlich |
Sämtliche Einstellungen prüfen und an die eigenen Anforderungen anpassen |
Einstellungen für In-App-Daten prüfen und an die eigenen Anforderungen anpassen |
Quelle: Atlassian Support — Data contribution settings
Schutzmaßnahmen und ihre Grenzen
Atlassian beschreibt mehrere Schutzmaßnahmen: Sowohl Metadaten als auch In-App-Daten werden vor der Nutzung de-identifiziert und aggregiert. Direkt identifizierende Informationen wie Namen oder E-Mail-Adressen werden entfernt; zusätzlich sollen Kontrollen eine Re-Identifikation verhindern. Bei den „Common Patterns“ greift laut Atlassian ein weiterer Schutzmechanismus: Inhalte, die einer einzelnen Organisation zugeordnet werden könnten, werden bereits vor der Extraktion ausgeschlossen.
Im Fall eines Opt-outs oder einer Löschung werden In-App-Daten innerhalb von 30 Tagen und Metadaten innerhalb von 90 Tagen aus den entsprechenden Datensätzen entfernt; bereits trainierte Modelle sollen anschließend angepasst werden. De-identifizierte und auf Kundenebene aggregierte Daten — einschließlich der Common Patterns — können hingegen bis zu sieben Jahre gespeichert bleiben. Atlassian begründet diesen Zeitraum damit, dass sich über längere Zeiträume aussagekräftigere Beobachtungen gewinnen ließen. Zudem erklärt das Unternehmen, dass bestehende Data-Residency-Einstellungen auch für beigetragene In-App-Daten weiterhin gelten und die Unterstützung der GDPR-Compliance von Kundenorganisationen unverändert bleibt.
Dennoch ist eine wichtige Differenzierung erforderlich: Ob de-identifizierte Daten im konkreten Fall weiterhin als personenbezogene Daten im Sinne der DSGVO gelten, hängt maßgeblich vom jeweiligen Kontext und den verbleibenden Re-Identifizierungsrisiken ab. Diese rechtliche Bewertung sollte daher nicht pauschal mit Atlassians eigener Begrifflichkeit gleichgesetzt werden. Auch wenn Daten nur in de-identifizierter Form in Modelle einfließen, kann dies eine Verarbeitung darstellen, die im Verarbeitungsverzeichnis und gegebenenfalls auch in den Auftragsverarbeitungsverträgen berücksichtigt werden sollte.
Der Zeitrahmen im Überblick
Die Einführung erfolgt in vier Stationen, jeweils begleitet von definierten Hinweisen: von der Initialmail im April über In-Produkt-Hinweise während des Rollouts und eine explizite 90-Tage-Erinnerung bis hin zum Inkrafttreten am 17. August. 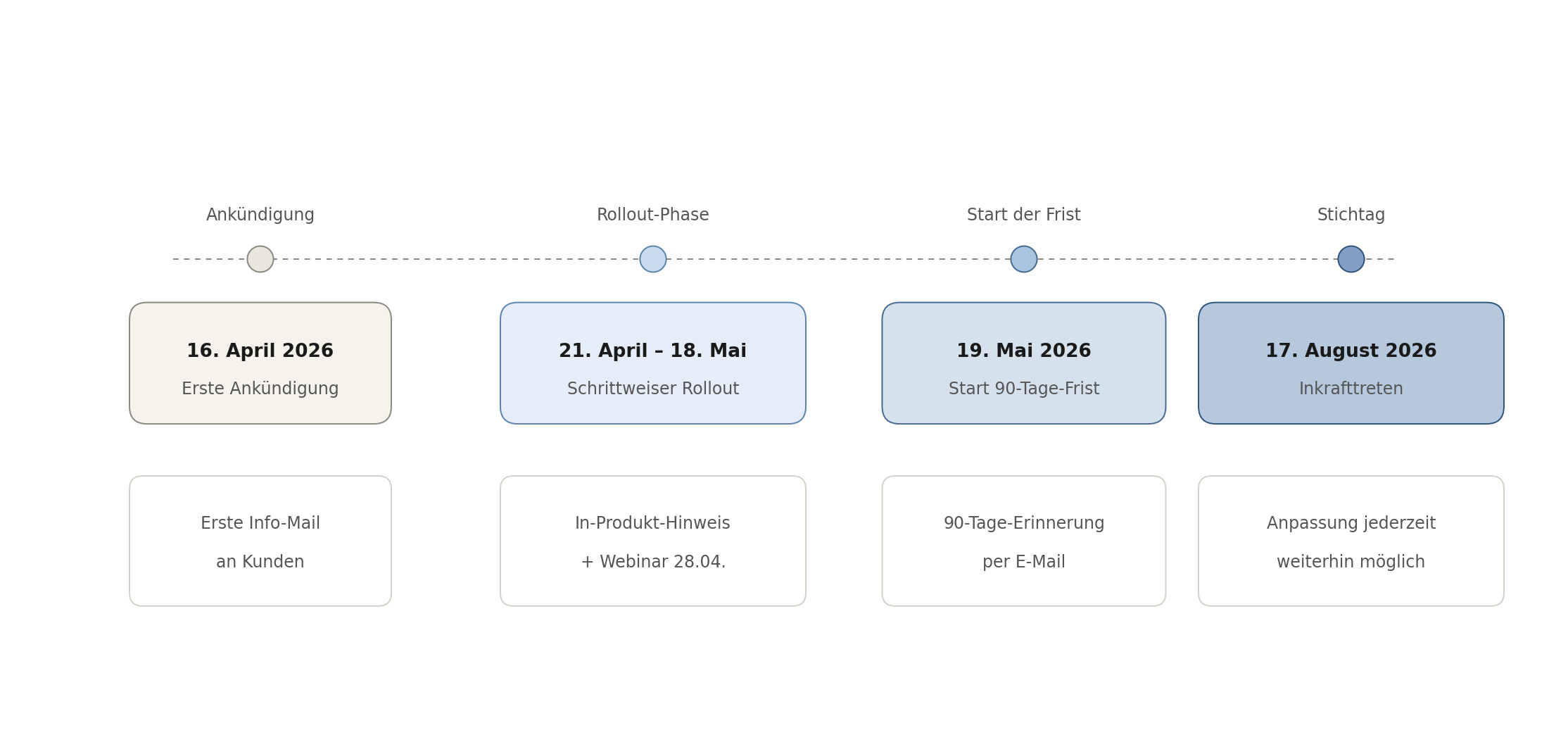
Was bei der Bewertung leicht übersehen wird
Die Einstellung in der Atlassian Administration ist schnell angepasst. Die eigentliche Entscheidung ist jedoch weit mehr als eine technische Konfigurationsfrage. Sie betrifft gleichermaßen organisatorische, rechtliche und vertragliche Aspekte. Vier Punkte verdienen dabei besondere Aufmerksamkeit.
Erstens: Die Entscheidung hat eine vertragliche Dimension. Zum Stichtag aktualisiert Atlassian nicht nur die Administrationseinstellungen, sondern auch das Customer Agreement, die AI Terms, das Data Processing Addendum sowie die Privacy Policy. Die gewählte Konfiguration sollte daher mit internen Richtlinien, bestehenden Vertragsanlagen und der datenschutzrechtlichen Dokumentation konsistent sein.
Zweitens: In Jira Service Management und kundenorientierten Jira-Projekten werden häufig Daten Dritter verarbeitet — etwa Kundenkommunikation, Beschwerden, Vertragsinformationen oder die Namen externer Ansprechpartner. Organisationen sollten deshalb prüfen, ob Datenschutzdokumentation, Betroffeneninformationen, Kundenverträge und interne Schutzklassifizierungen eine Nutzung dieser Inhalte zur Plattformverbesserung abdecken. Falls nicht, kann es sinnvoll sein, den Beitrag von In-App-Daten für bestimmte Bereiche gezielt zu deaktivieren.
Drittens: Planwechsel und Trials können die Ausgangslage verändern. Die Standardeinstellungen orientieren sich am jeweils höchsten aktiven Plan innerhalb der Organisation — einschließlich Testversionen. Zusätzlich sollte regelmäßig überprüft werden, welche Apps, Spaces und Connectors tatsächlich ein- oder ausgeschlossen sind, anstatt sich dauerhaft auf einmal gesetzte Standardwerte zu verlassen.
Viertens: De-identifiziert bedeutet nicht automatisch risikofrei. Zwar entfernt Atlassian direkte Identifikatoren und arbeitet mit aggregierten Daten. Dennoch sollten Organisationen bewerten, ob häufig auftretende, zugleich aber kontextreiche Inhalte aus Jira oder Confluence Rückschlüsse auf interne Vorhaben, Kundenbeziehungen oder sensible Prozesse ermöglichen könnten.
Damit verschiebt sich der Fokus der Diskussion: Entscheidend ist nicht allein, ob ein bestimmter Toggle aktiviert oder deaktiviert wird, sondern ob die zugrunde liegende Entscheidung organisatorisch, rechtlich und technisch langfristig tragfähig ist.
Eine bewusste Entscheidung — keine Default-Entscheidung
Zwischen den Polen „Daten zurückhalten“ und „Daten beitragen“ liegt ein breites und durchaus legitimes Entscheidungsspektrum. Die kollektive Weiterentwicklung der Atlassian Plattform kann einen realen Mehrwert schaffen, von dem letztlich auch die eigene Organisation profitiert. Gleichzeitig ist die Kontrolle über eigene Inhalte ein berechtigtes Schutzinteresse — insbesondere in regulierten Branchen oder bei sensiblen internen Prozessen.
Eine pauschale Empfehlung in die eine oder andere Richtung wäre daher wenig seriös. Klar ist jedoch: Diese Abwägung sollte nicht dem Default überlassen werden, sondern das Ergebnis einer bewussten und nachvollziehbar dokumentierten Entscheidung sein. Idealerweise wird diese Entscheidung vor dem 17. August 2026 getroffen.
Als Atlassian-Partner begleitet HanseVision Organisationen dabei, diesen Entscheidungsprozess strukturiert aufzusetzen — von der Bestandsaufnahme über das Stakeholder-Alignment bis hin zur sauberen technischen Konfiguration. Wer den Prozess nicht vollständig intern abbilden möchte, kann sich jederzeit an uns wenden.
Wenn Sie das für Ihre Organisation prüfen möchten, sprechen Sie uns gerne an.
Quellen
Sämtliche Faktenangaben in diesem Beitrag stützen sich auf Atlassians eigene Dokumentation (abgerufen am 30. April 2026):
-
Atlassian Trust Center — Data practices built for responsible AI
-
Atlassian Trust Center — Data Contributions Frequently Asked Questions
-
Atlassian Support — What types of data does my organization contribute?
.png?width=384&height=241&name=Design%20ohne%20Titel%20(8).png)
.png?width=384&height=241&name=Design%20ohne%20Titel%20(9).png)